Abstract
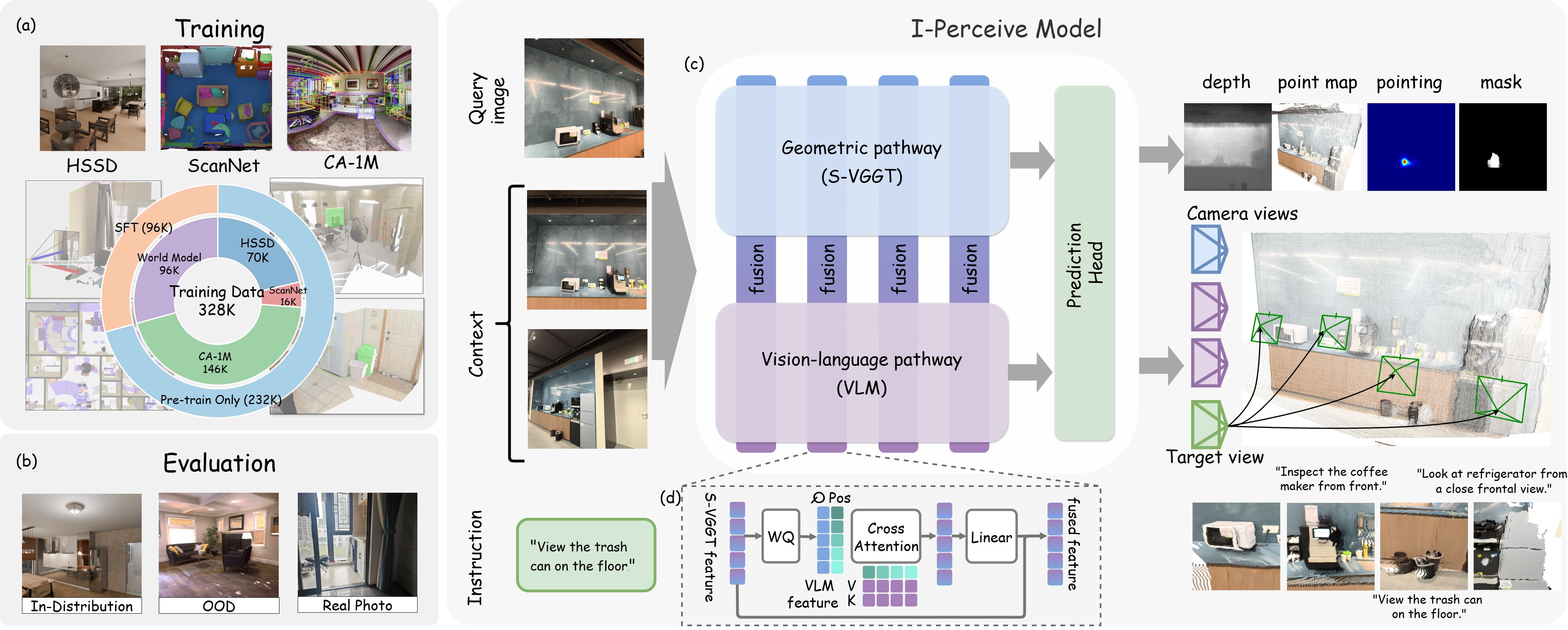
Active perception, the ability of a robot to proactively adjust its viewpoint to acquire task-relevant information, is essential for robust operation in unstructured real-world environments. While critical for downstream tasks such as manipulation, existing approaches have largely been confined to local settings (e.g., table-top scenes) with fixed perception objectives (e.g., occlusion reduction). Addressing active perception with open-ended intents in large-scale environments remains an open challenge. To bridge this gap, we propose I-Perceive, a foundation model for active perception conditioned on natural language instructions, designed for mobile manipulators and indoor environments. I-Perceive predicts camera views that follows open-ended language instructions, based on image-based scene contexts. By fusing a Vision-Language Model (VLM) backbone with a geometric foundation model, I-Perceive bridges semantic and geometric understanding, thus enabling effective reasoning for active perception.We train I-Perceive on a diverse dataset comprising real-world scene-scanning data and simulation data, both processed via an automated and scalable data generation pipeline. Experiments demonstrate that I-Perceive significantly outperforms state-of-the-art VLMs in both prediction accuracy and instruction following of generated camera views, and exhibits strong zero-shot generalization to novel scenes and tasks.